Benchmarking Supervised Learning Algorithms on Real-World Datasets
KNN, SVM & Neural Networks
PYTORCH
SCIKIT-LEARN
When it comes to choosing a supervised learning algorithm, there’s no one-size-fits-all solution. This project takes a closer look at three foundational machine learning models—Support Vector Machines (SVM), k-Nearest Neighbors (KNN), and Neural Networks (NN)—and puts them through their paces on two very different datasets. The objective is to assess each algorithm's predictive accuracy, computational efficiency, and sensitivity to hyperparameter tuning.
Datasets and Experimental Setup
Two datasets with contrasting characteristics were selected:
Phishing Website Detection (Dataset 1): A binary classification problem with 30 categorical features. The dataset is balanced and exhibits moderate feature-target correlations, making it well-suited for traditional classification algorithms.
Wine Quality Prediction (Dataset 2): A more challenging multi-class classification task involving 12 continuous features and imbalanced class distribution. The weak feature-target correlations further increase the complexity.
All models were implemented in Python using Scikit-learn (SVM, KNN) and PyTorch (NN). An 80/20 train-test split was used, along with 5-fold cross-validation. The weighted F1 score was chosen as the evaluation metric to account for class imbalance. Each model’s performance was assessed after hyperparameter tuning through grid search.
Summary of Findings
Support Vector Machines (SVM)
SVM demonstrated the highest overall performance on the phishing dataset (F1 score: 0.975). With RBF kernels and carefully tuned gamma and C parameters, the model maintained a strong generalization profile. On the wine dataset, SVM still performed well but showed signs of overfitting at higher complexity levels.

k-Nearest Neighbors (KNN):
KNN was the fastest to train and performed particularly well in detecting underrepresented classes in the wine dataset, likely due to its robustness to outliers. The optimal neighbor count was 14 for the phishing dataset and 11 for the wine dataset. However, it had slightly lower predictive accuracy overall and higher inference time.
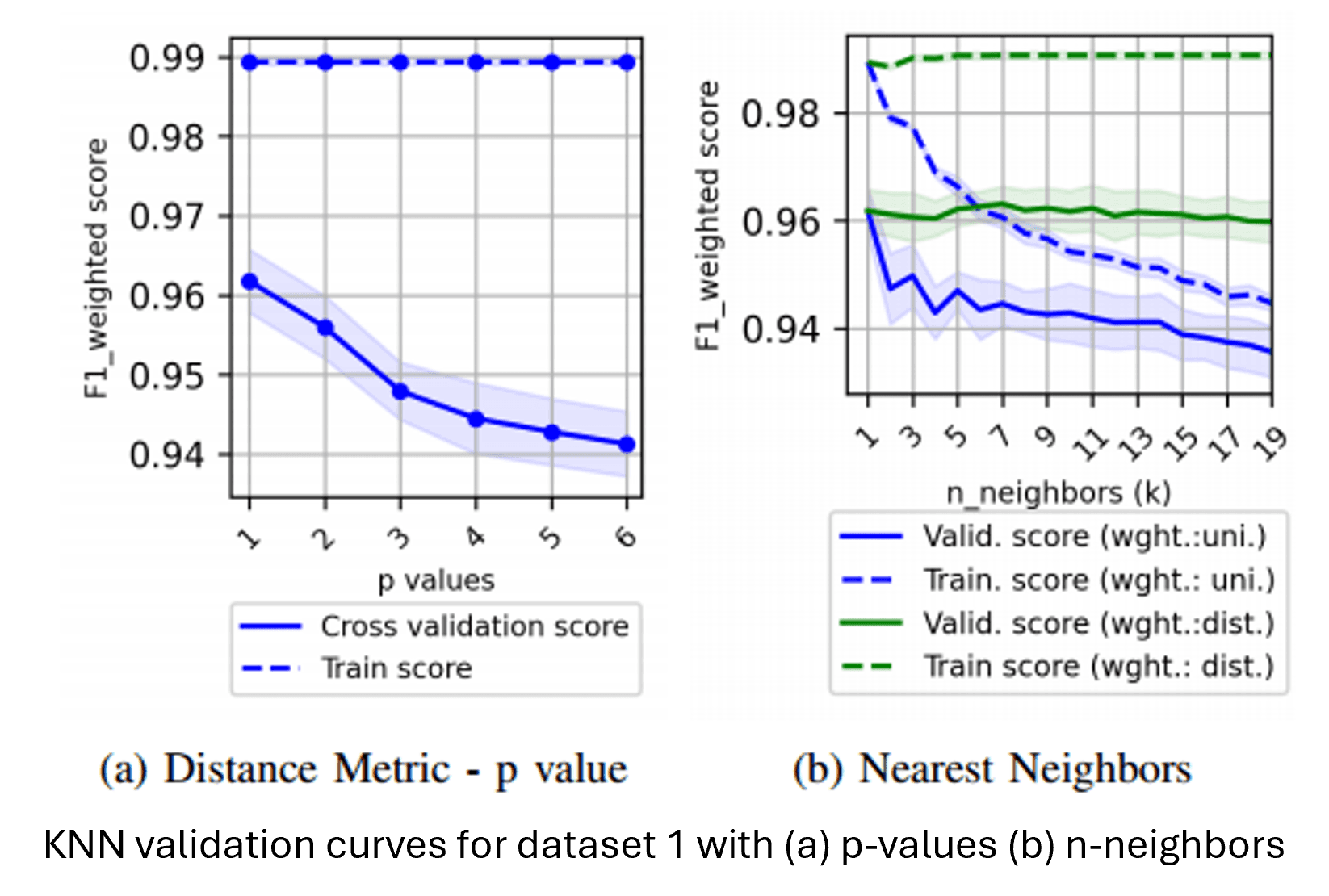
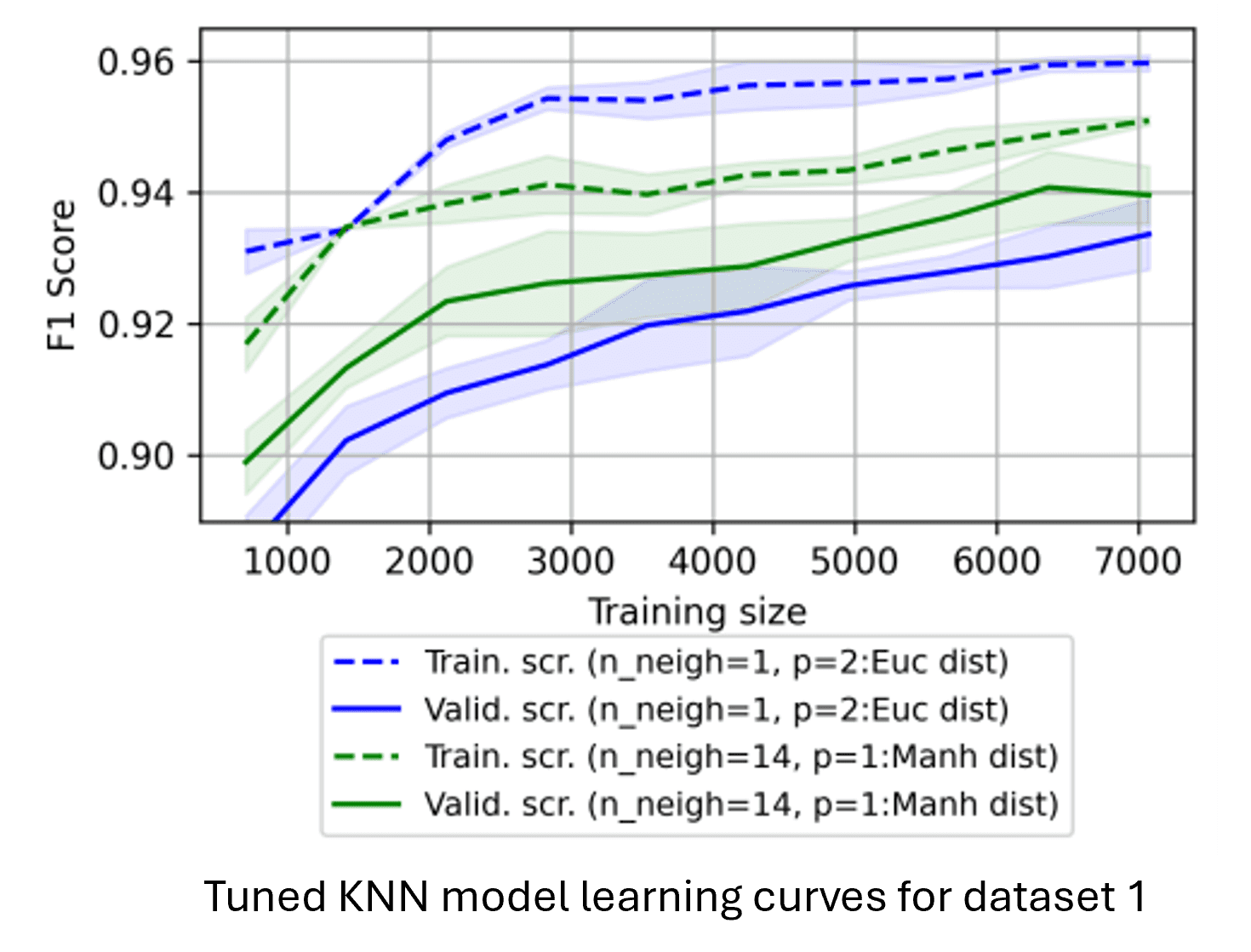
Neural Networks (NN):
Neural Networks achieved competitive results on the phishing task (F1 score: 0.958), but required extensive tuning of learning rate, hidden layer size, and training epochs. A single hidden layer with 70–100 units was optimal. On the wine dataset, the model was prone to overfitting and struggled with minority class prediction.

Final Thoughts
This study highlights the importance of aligning algorithm choice and tuning strategy with the characteristics of the dataset. SVM proved to be the most consistent performer, KNN offered simplicity and interpretability, and Neural Networks demonstrated potential with sufficient tuning and data volume. Each model presents unique trade-offs that must be carefully considered in practical applications.

Published April 2025
Go back home