Dimensionality Reduction and Clustering for Real-World Classification Tasks
PYTORCH
SCIKIT-LEARN
In unsupervised learning, algorithms attempt to uncover hidden patterns or simplify data structure without the use of labeled outputs. Two common strategies are dimensionality reduction, which compresses feature space while preserving key information, and clustering, which groups similar data points based on intrinsic characteristics. This project investigates the role of these techniques in unsupervised learning workflows and their downstream effects on neural network performance. Using two real world datasets, Phishing Website Features and Wine Quality Prediction, this study evaluates how well methods like PCA, ICA, and Random Projections compress data without sacrificing predictive utility, and how K-Means and Expectation Maximization (EM) uncover latent structure.
Datasets and Experimental Setup
Phishing Website Detection: A high-dimensional, balanced binary classification task with 30 categorical features. It presents moderate linear correlation among features and is well-suited for dimensionality reduction techniques.
Wine Quality Prediction: A more complex three-class classification problem with weak feature-target correlation and class imbalance, derived from physicochemical properties.
Experiments were conducted using Scikit-learn (for clustering and reduction), and PyTorch (for neural networks) libraries. Dimensionality reduction and clustering were only performed on the training set to avoid data leakage. KNN algorithm was used for performance validation, and neural networks were later trained on both original and transformed datasets for dimensionality reduction performance testing.
Summary of Findings
Dimensionality Reduction
PCA: Reduced feature counts by ~17–18% while preserving >97% variance. For both datasets, PCA-transformed versions slightly improved or maintained KNN F1 scores while decreasing prediction times.
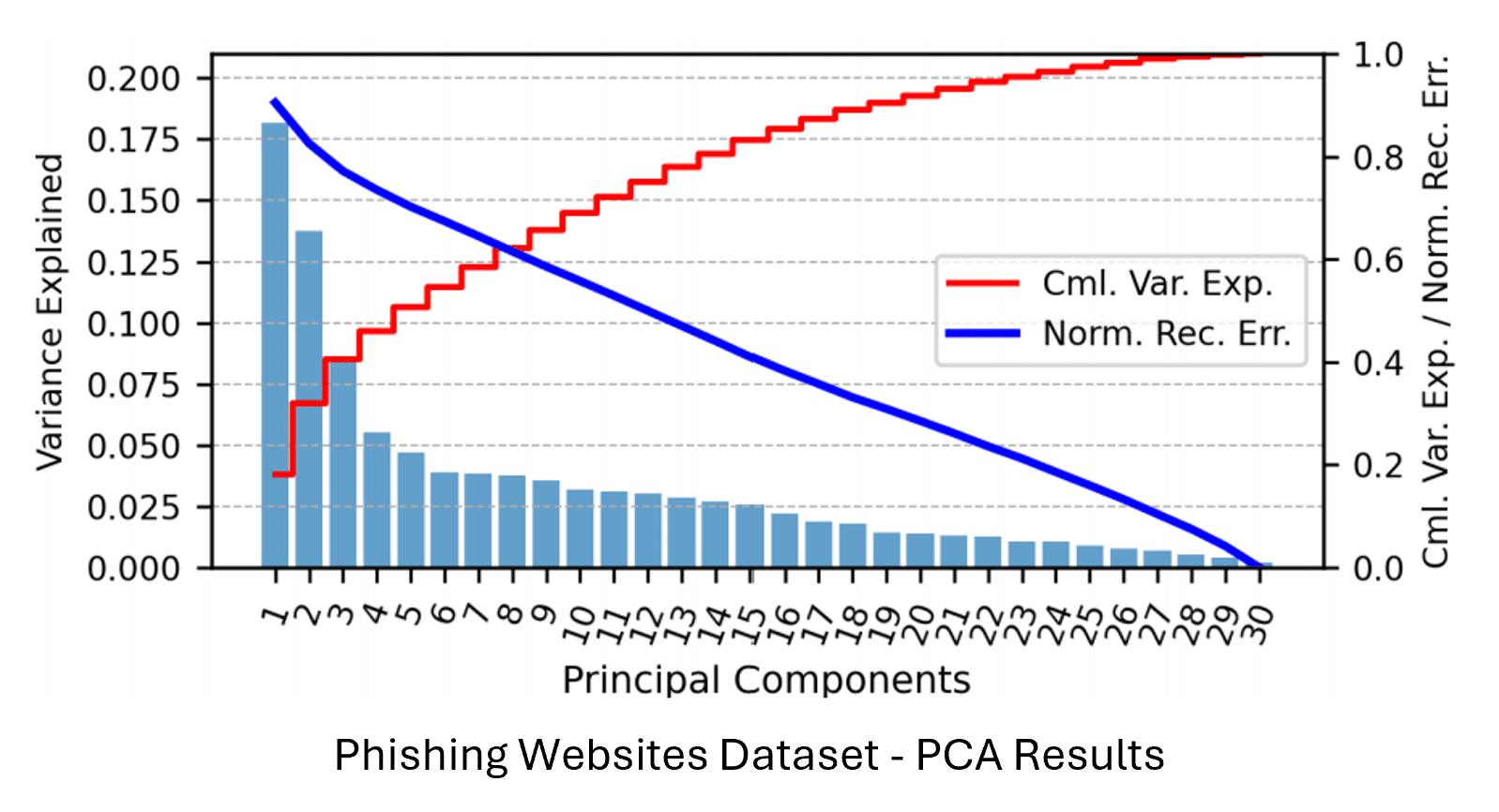
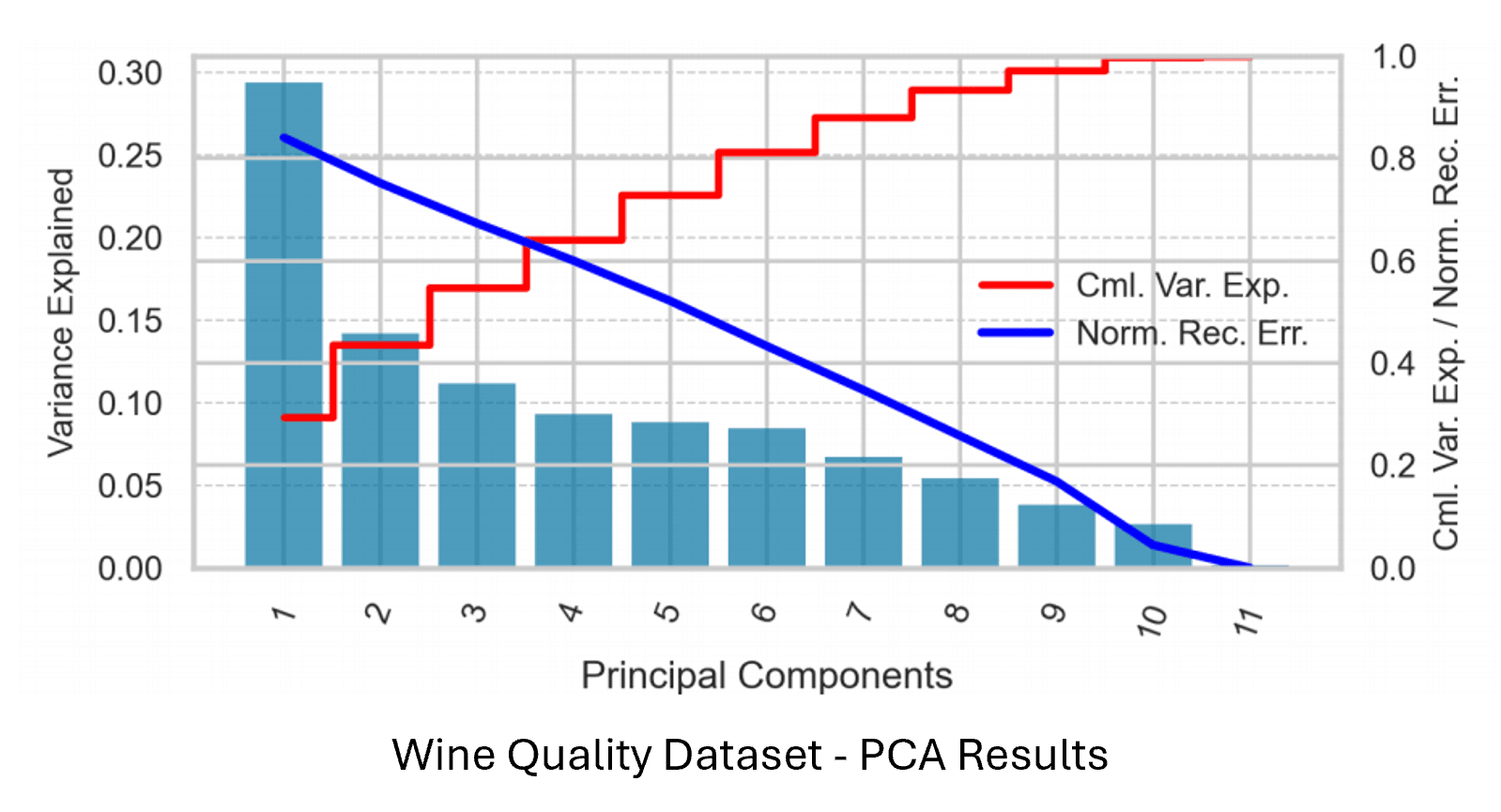
ICA: Achieved slightly better F1 scores than PCA while also reducing model complexity and training time in neural network tasks—particularly effective for the phishing dataset.
Random Projections: Provided modest speedups but reduced F1 performance, indicating possible information loss.
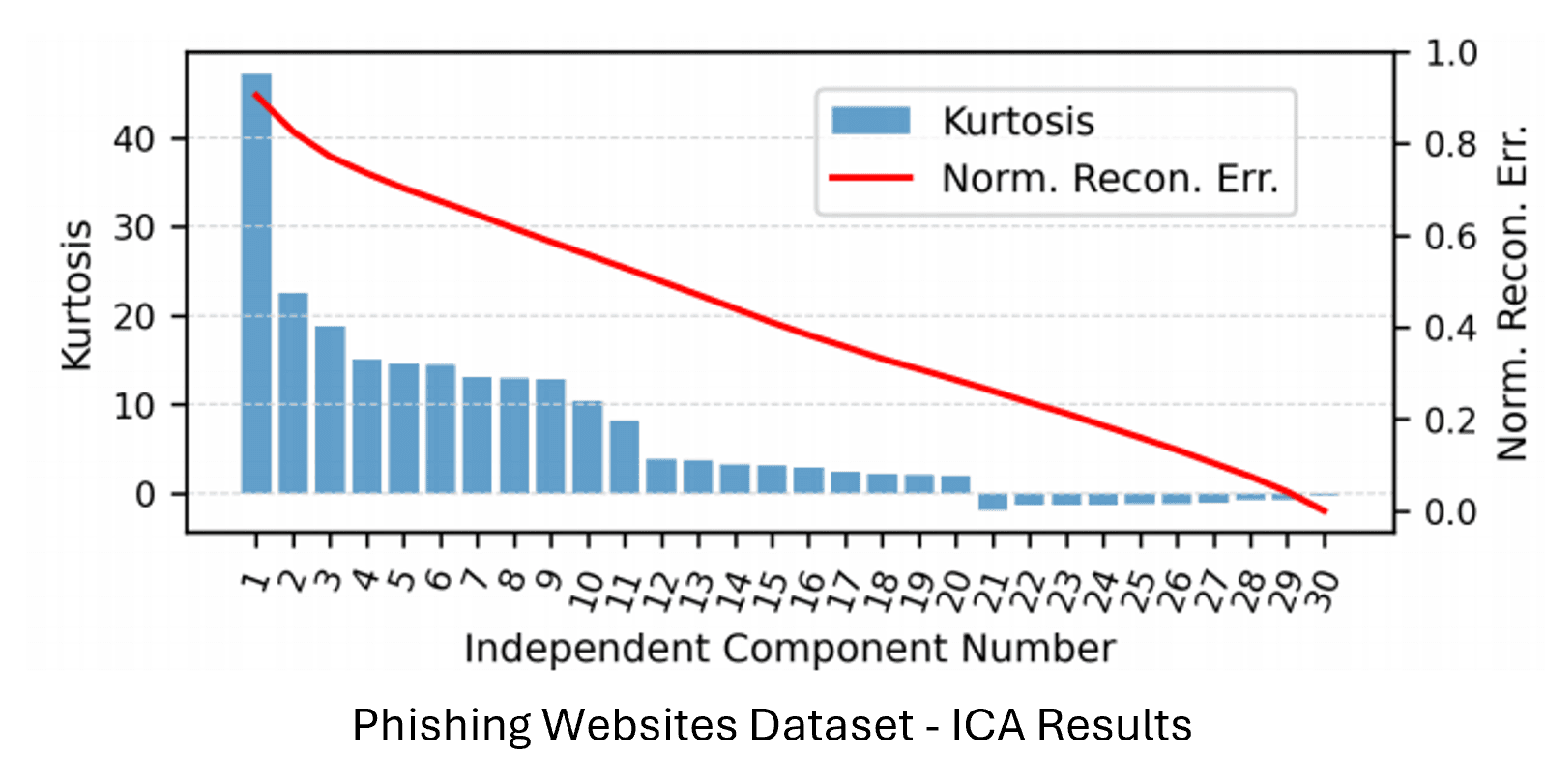
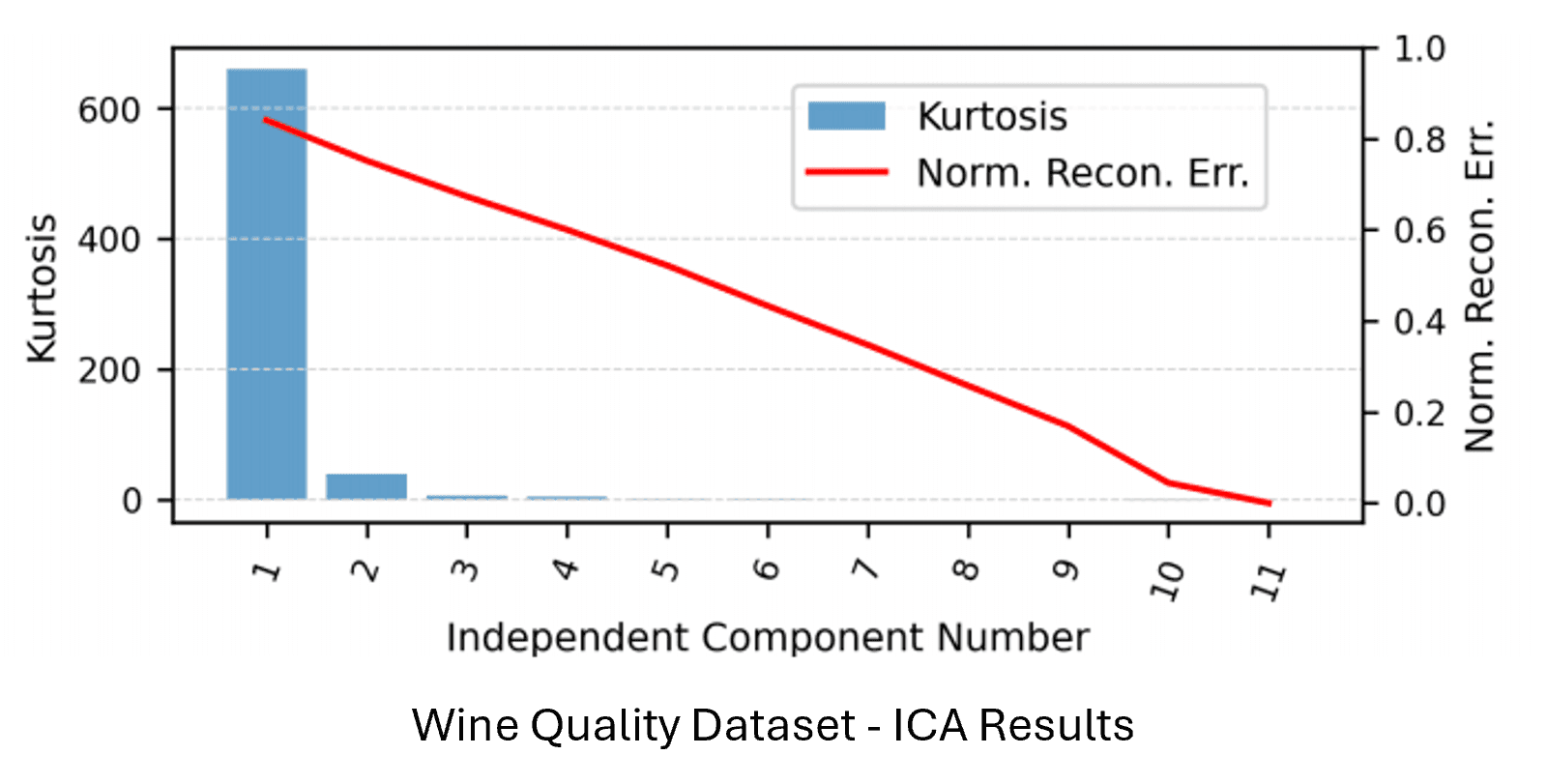
Clustering Algorithms
K-Means: Identified 4 clusters for phishing (suggesting gradations of risk) and 7 for wine (mirroring original rating classes). PCA and ICA-transformed versions performed worse than raw data, but RP maintained similar results.
Expectation Maximization (EM): Showed improved F1 and homogeneity scores on ICA-reduced data but was more computationally intensive and overfit easily, especially on the higher-dimensional phishing dataset.

Neural Networks Impact
Training neural networks on ICA-reduced data achieved nearly identical performance with lower training time (ICA: F1 0.9231 vs. Original: F1 0.9314). Adding cluster labels as features slightly increased complexity without meaningful performance gain, suggesting redundancy.
Final Thoughts
Unsupervised learning techniques like dimensionality reduction and clustering can enhance model interpretability and efficiency, but their effectiveness depends heavily on dataset structure. ICA proved most effective in balancing compression and performance, while PCA offered the best trade-off for simplicity. Clustering insights were more nuanced, useful for exploratory analysis but less beneficial when used as new neural net features. These findings reinforce the importance of aligning technique choice with data characteristics and downstream goals.
Published April 2025
Go back home