From Single-Label Training to Multi-Label Prediction: Third Place at PlantCLEF 2026
PyTorch
PySpark
SLURM
FAISS




PlantCLEF presents an unusual computer vision challenge. Models must identify every plant species present in a high-resolution vegetation survey image, known as a quadrat, where multiple species may appear side by side, overlap, or grow densely intertwined, despite being trained almost entirely on images of individual plants.
Automating plant species identification has applications far beyond building a better image classifier. Vegetation surveys are a fundamental tool in biodiversity monitoring, ecological research, conservation planning, and climate change studies. From a machine learning perspective, however, the challenge extends beyond ecology. Similar problems appear in medical imaging, satellite imagery, precision agriculture, industrial inspection, and autonomous systems, where models must identify multiple co-occurring objects, operate under significant domain shift, and incorporate contextual information that may not be visible in the image itself. PlantCLEF provides a particularly difficult instance of this broader class of computer vision problems.
The training dataset contains approximately 1.4 million labeled images spanning 7,806 species, with nearly every image being a close-up, depicting distinctive organs such as a flower, leaf, or stem. The test set looks very different: 3000×3000 pixel vegetation plots containing multiple overlapping species at varying scales. As a result, a model trained for single-label classification must perform multi-label scene understanding under severe domain shift, while preserving fine-grained visual cues that are easily lost during image down sampling.
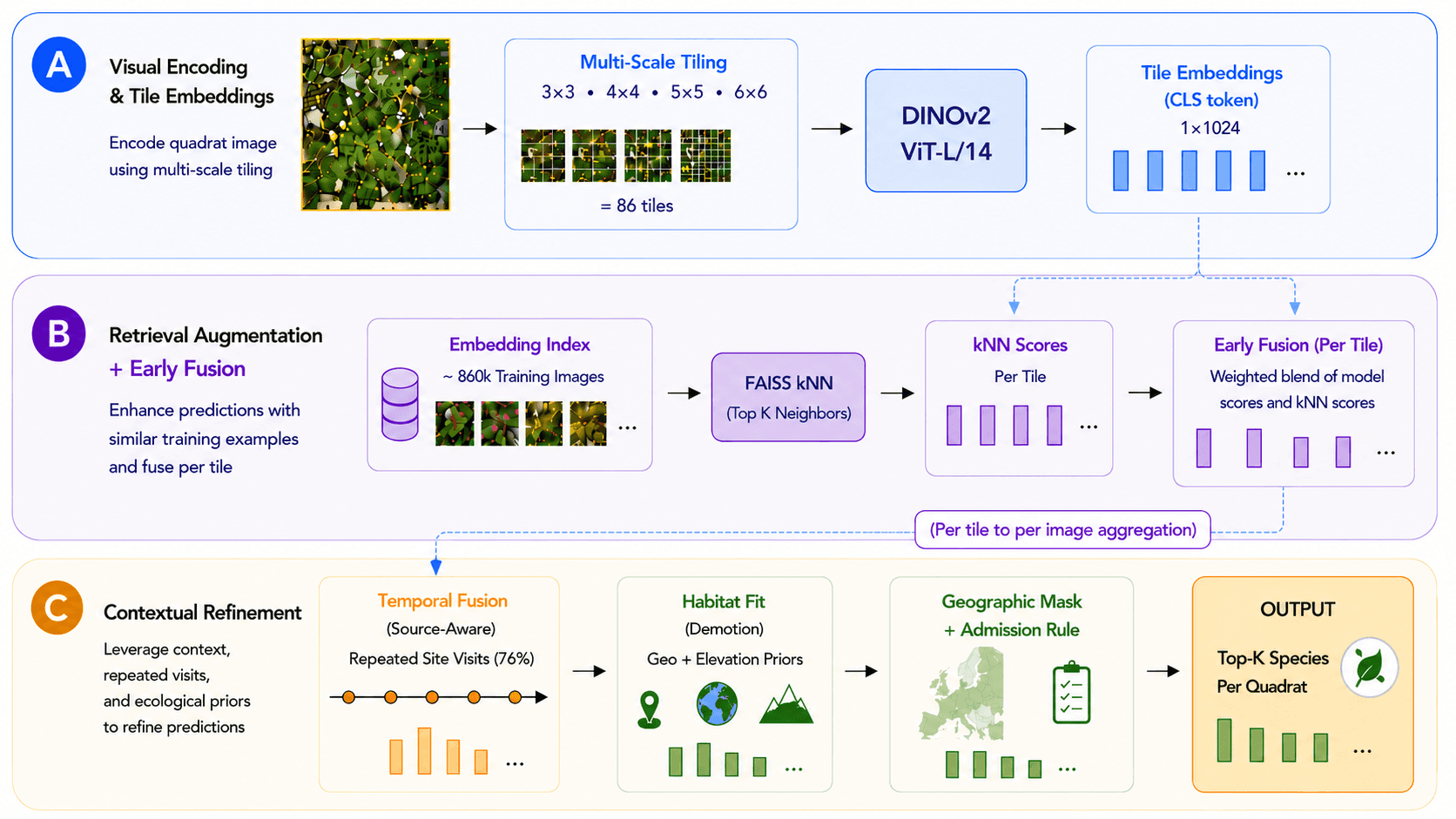
Our team placed third in the PlantCLEF 2026 competition. The final solution combined a fine-tuned DINOv2 ViT-L/14 backbone with multi-scale tile inference, similarity-based image retrieval, temporal fusion across repeated site visits, and ecological priors derived from geographic and elevation metadata.
This article describes the design of the final system, the ablation studies used to evaluate each component, and the lessons learned while addressing one of the more challenging domain-shift problems in fine-grained visual classification.
TL;DR
Challenge
Train on 1.4 million single-species plant images and predict all species present in high-resolution vegetation survey images.
Severe single-label → multi-label domain shift across 7,806 possible classes.
Test images are approximately 3000×3000 pixels, making fine-grained species identification difficult with standard Vision Transformer inputs.
Approach
Fine-tuned a DINOv2 ViT-L/14 classifier on the PlantCLEF training dataset.
Applied composite multi-scale tile inference using 3×3, 4×4, 5×5, and 6×6 grid decompositions to preserve fine-grained visual detail.
Blended classifier predictions with a FAISS kNN retrieval model.
Leveraged repeated observations of the same location through temporal fusion.
Incorporated geographic and elevation priors through habitat-fit post-processing.
Result
Achieved 0.45777 private leaderboard macro-F1 with the best pipeline configuration, placing 3rd overall in PlantCLEF 2026.
Main Lesson
The largest gains came from designing around the test distribution rather than improving the classifier itself.
Under severe domain shift, retrieval, aggregation, temporal consistency, and contextual priors contributed more than additional backbone improvements.
Task Setup
The training data is a subset of the Pl@ntNet collaborative database covering South-Western European flora: 1.4 million images spanning 7,806 species. The evaluation set consists of 2,105 high-resolution quadrats organized into ecological transects. Approximately 76% of test images belong to locations that were photographed multiple times throughout the year, creating an opportunity to leverage temporal consistency during inference.
System Overview
The final system combines a fine-tuned vision transformer with a series of inference-time components designed to address the severe train-test distribution gap:
DINOv2 ViT-L/14 classifier fine-tuned on the PlantCLEF training data.
Multi-scale tile inference using 3×3, 4×4, 5×5, and 6×6 grid decompositions (86 tiles per image).
Retrieval-augmented classification using FAISS nearest-neighbor search.
Source-aware temporal fusion across repeated observations of the same location.
Habitat-aware post-processing using geographic and elevation priors, supplemented by a geographic mask and admission rule.
The strongest pipeline configuration achieved a private leaderboard macro-F1 of 0.45777. Notably, the largest single improvement came from habitat-aware post-processing rather than changes to the underlying model architecture.
The remainder of this article examines each component individually and quantifies its contribution through ablation analysis.
Fine-Tuning the Backbone
The foundation of the system is a DINOv2 ViT-L/14 model containing approximately 300 million parameters. The competition organizers provide a ViT-B/14 checkpoint already fine-tuned on the PlantCLEF training set, which served as the baseline for many prior submissions. ViT-L/14 was selected as the primary backbone in our setup because inference cost was not a significant constraint and prior years had already explored many of the simpler improvements available on top of ViT-B.
Training followed a standard two-phase fine-tuning procedure. First, a 7,806-class classification head was trained on a frozen backbone at 518×518 resolution. The backbone was then unfrozen and optimized for 30 epochs using AdamW, layer-wise learning-rate decay (0.85), drop-path regularization (0.3), RandAugment, MixUp, CutMix, and exponential moving average (EMA).
To isolate the impact of model capacity, the same multi-scale inference pipeline was later evaluated using the organizer-provided ViT-B checkpoint. Under the baseline 4×4 configuration, replacing ViT-B with ViT-L improved macro-F1 by 0.02171. Across additional scale configurations, the gain ranged from approximately 0.022 to 0.052 F1. Both backbones converged on the same optimal scale configuration, suggesting that scale selection was driven primarily by properties of the evaluation data rather than backbone capacity.
Multi-Scale Tile Inference
Directly resizing a 3000×3000 vegetation survey image to the fixed input resolution expected by a Vision Transformer discards many of the fine-grained visual cues required for species identification. To address this limitation, each image was processed at multiple spatial scales.
For each scale (s \in {3,4,5,6}), the image was center-cropped, resized to ((518 \cdot s) \times (518 \cdot s)), and partitioned into (s^2) non-overlapping 518×518 tiles. This produced a total of 86 tiles per image across all scales. Each tile was independently classified and converted to a temperature-scaled probability distribution ((T = 1.5)). Predictions were then aggregated using per-class max pooling:
Max pooling proved particularly effective because it preserves the strongest local evidence for each species independently. A species occupying only a small region of a single tile can still contribute strongly to the final prediction, preventing rare or spatially localized species from being diluted during aggregation. After pooling, predictions were truncated to the top-64 classes to improve the stability of downstream fusion stages.
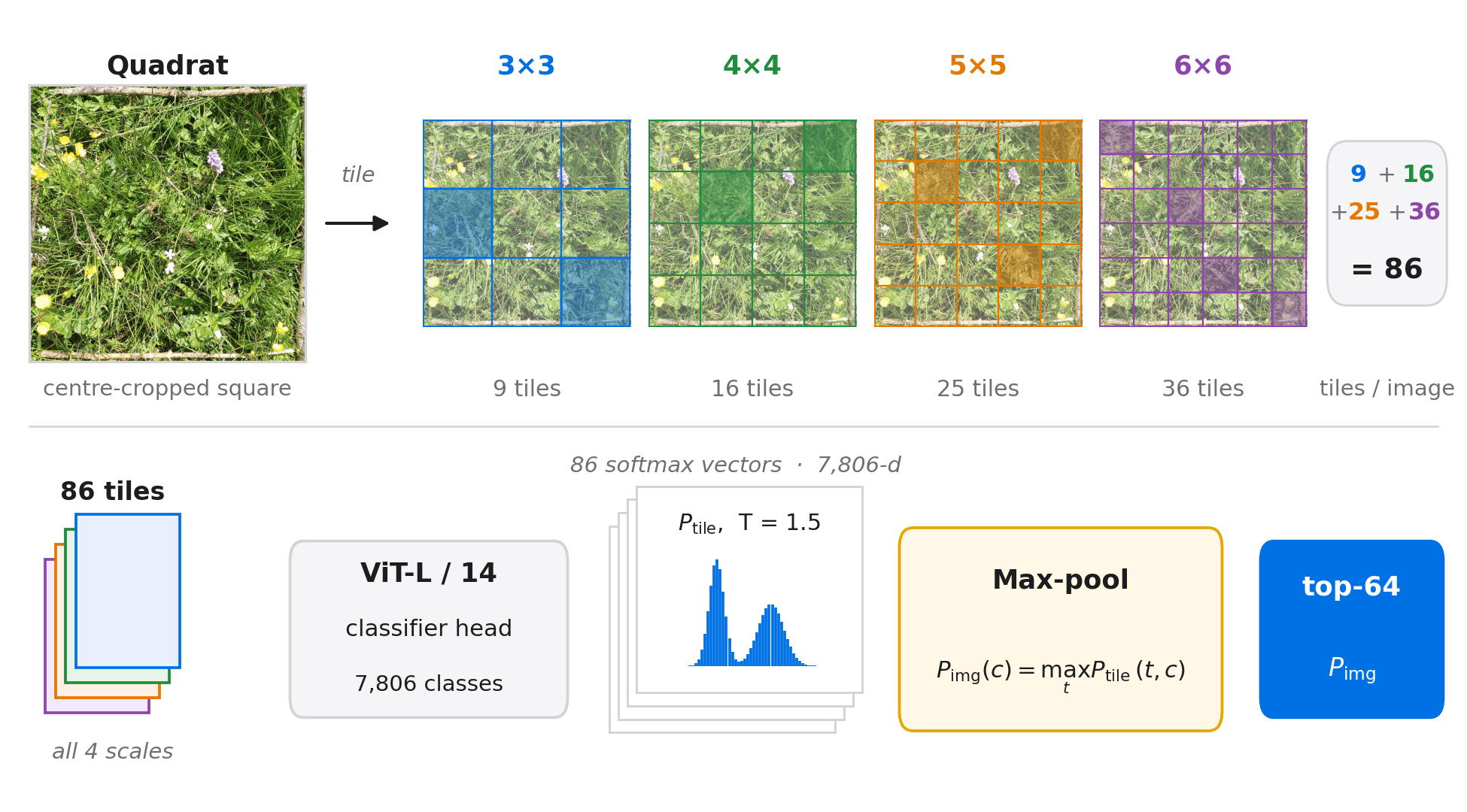
Scale-selection experiments revealed a non-monotonic relationship between performance and the number of scales included. Adding additional scales did not always consistently improve results. While larger scale sets (where 7x7 and 8x8 scales were also added) occasionally produced higher validation scores, the {3,4,5,6} configuration proved the most robust and was retained in the final system.
More broadly, this result highlights an important characteristic of high-resolution vision tasks: preserving local detail can be more valuable than increasing model capacity. Multi-scale tiling effectively transforms a scene-level classification problem into a collection of fine-grained local recognition tasks, allowing the model to retain visual evidence that would otherwise be lost during down-sampling.
Retrieval-Augmented Classification
To complement the classifier, the system incorporates an image-retrieval component. A LoRA adapter (rank 16) trained with an ArcFace margin objective was attached to the ViT-L backbone, producing 1024-dimensional L2-normalized CLS embeddings. These embeddings were used to construct a FAISS IndexFlatIP containing approximately 860,000 geo-filtered training examples.
At inference time, each tile queries the index for its top-20 nearest neighbors. Similarity scores are converted into a temperature-scaled softmax distribution ((\tau = 0.07)), aggregated by class, and blended with the classifier output prior to tile aggregation:
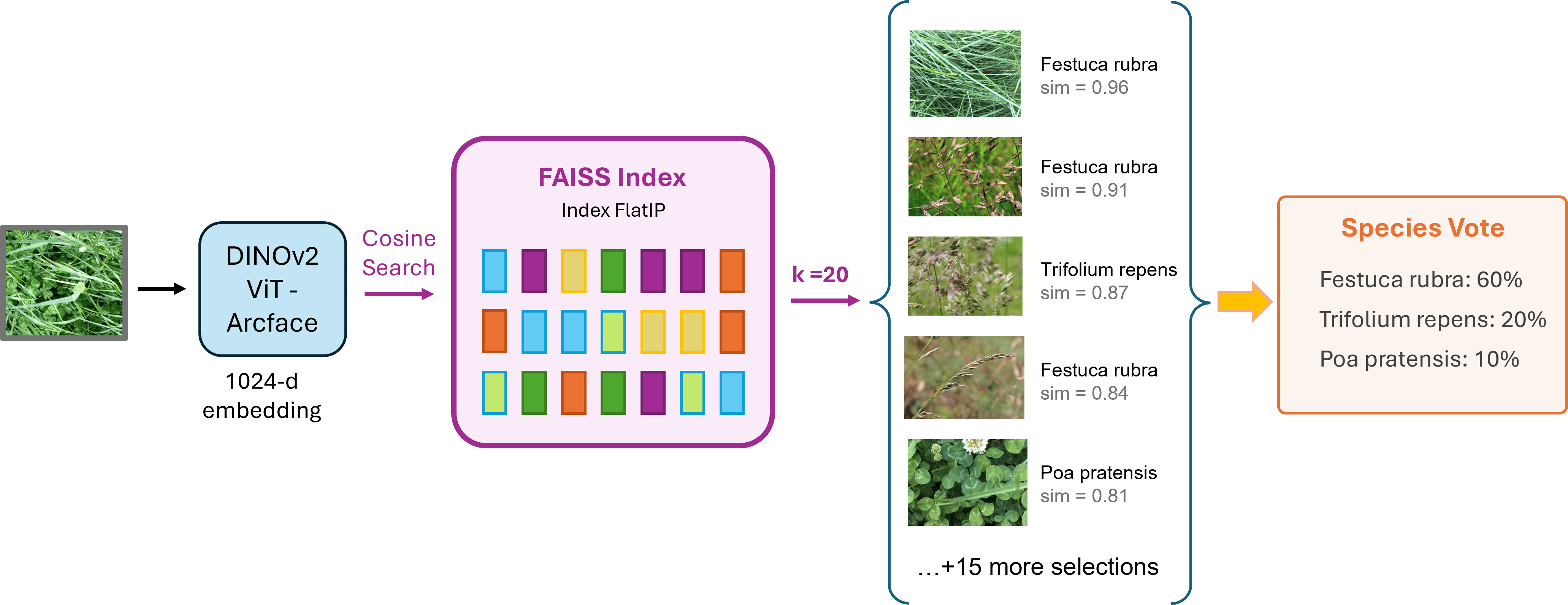
Ablation studies revealed a clear asymmetry in retrieval performance. While kNN retrieval improved results on multi-visit quadrats, it degraded performance on single-visit quadrats by as much as 0.08 F1. Early experiments applying retrieval uniformly across all samples consistently underperformed more selective strategies.
To address this behavior, a visit-aware retrieval schedule was introduced. Retrieval was blended with classifier predictions using (\beta = 0.70) for multi-visit quadrats, while retrieval was disabled entirely ((\beta = 1.00)) for single-visit quadrats. These single-visit locations tend to represent more unusual and challenging examples, where nearest-neighbor voting introduces noisy long-tail predictions rather than useful signal.
Temporal Fusion
Approximately 76% of the PlantCLEF evaluation set consists of repeated observations of the same physical location. Since species composition is generally stable across visits, predictions from related observations were aggregated to construct a location-aware prior:
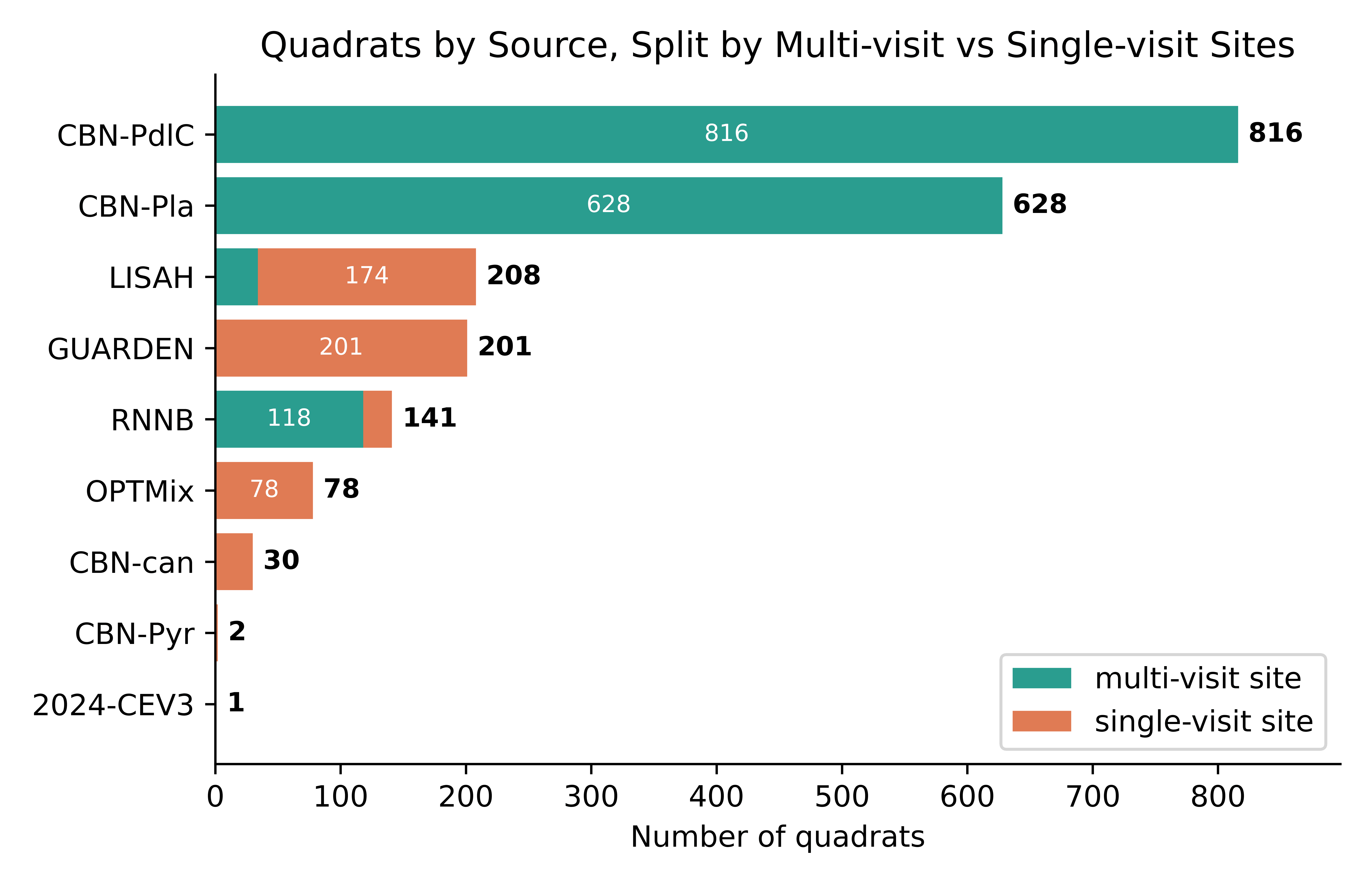
Quadrats were grouped by location using identifiers extracted from the quadrat_id field. For most collection sources, location priors were computed using max aggregation across sibling observations. A similarity-weighted variant based on embedding cosine similarity was evaluated for highly seasonal sites and retained only for the RNNB source, where it consistently improved performance.
Temporal fusion contributed a modest but consistent improvement, demonstrating that repeated observations can provide useful contextual information beyond what is available from any single image.
Habitat-Aware Post-Processing
After classifier prediction, retrieval blending, and temporal fusion, the model produces a probability distribution for each quadrat based on image content. However, PlantCLEF also provides metadata on the training image source altitude and coordinates. To take advantage of this additional information, each source in the test images is assigned to a distinct ecological regime, such as alpine environments, Mediterranean scrublands, or coastal salt marshes, with known geographic and elevation characteristics, derived from geographic and elevation statistics computed from the training data.
The geographic component measures how frequently a species has been observed within 250 km of a source's geographic centroid. Species with at least 40 nearby observations receive no penalty, while species with no nearby observations are down-weighted to (\beta = 0.10). The elevation component applies an analogous adjustment using altitude distributions, penalizing species whose median elevation differs substantially from the source's expected elevation band.
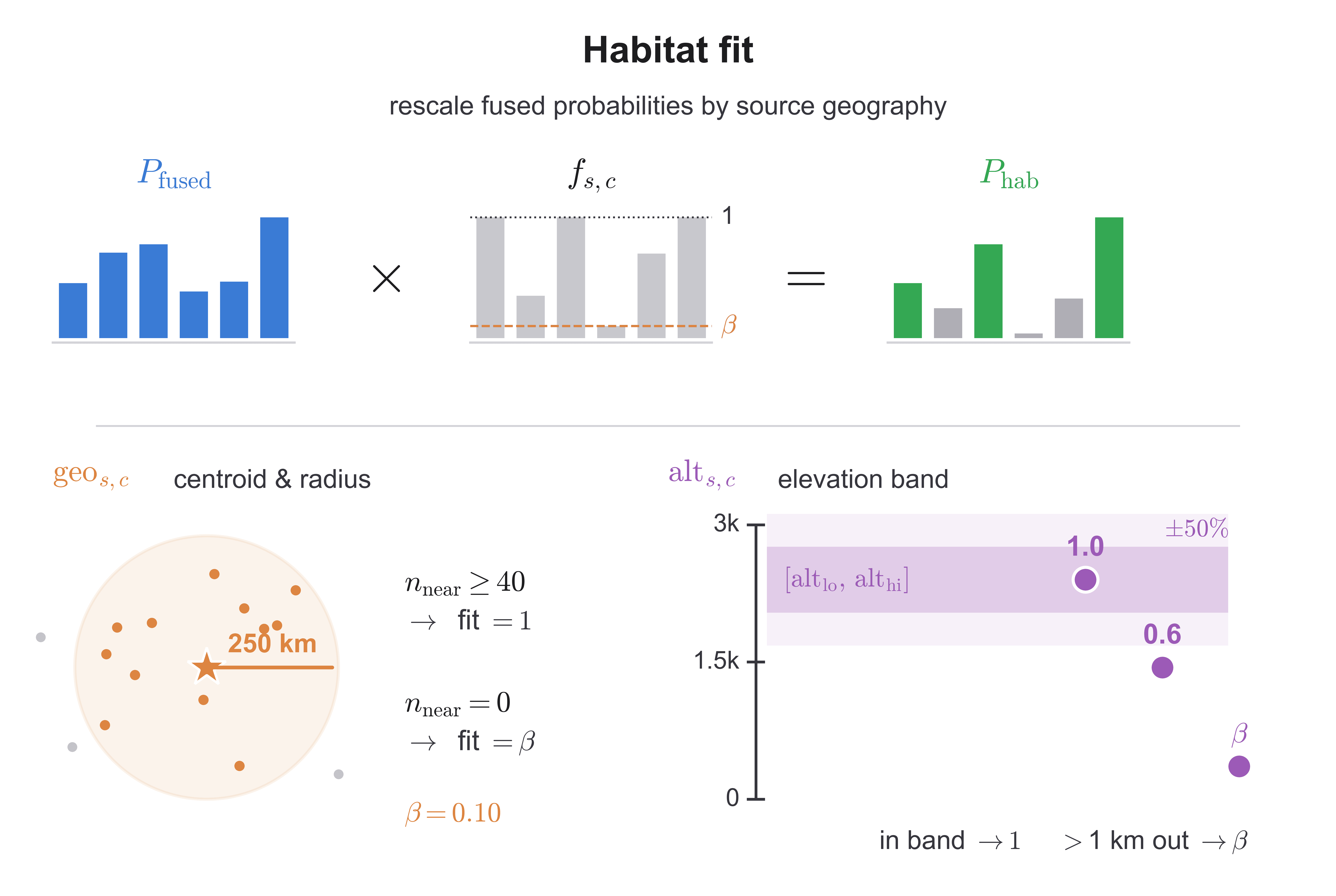
Following habitat-fit adjustment, a coarse South-Western Europe geographic mask removes approximately 3,000 species whose training-set centroids fall outside France, Spain, Italy, and Switzerland. A final admission rule retains classes with (P \ge 0.085) up to the top-10 predictions, while a fallback mechanism admits near-tied candidates when too few classes survive thresholding.
Applying habitat-fit and the associated geographic constraints improved macro-F1 by 0.04075, nearly twice the impact of any other component in the system. This is unsurprising: the information provided by habitat-fit is fundamentally unavailable to the image classifier itself. When relevant information exists outside the image itself, contextual priors can contribute more than additional model capacity. In this case, geographic location and elevation provided information that no architectural modification could directly recover from pixels alone.
Results and Ablation Analysis
The final pipeline achieved a peak macro-F1 score of 0.45777.
To quantify the contribution of each component, the system was constructed incrementally, starting from a ViT-B baseline and adding each major component one at a time.
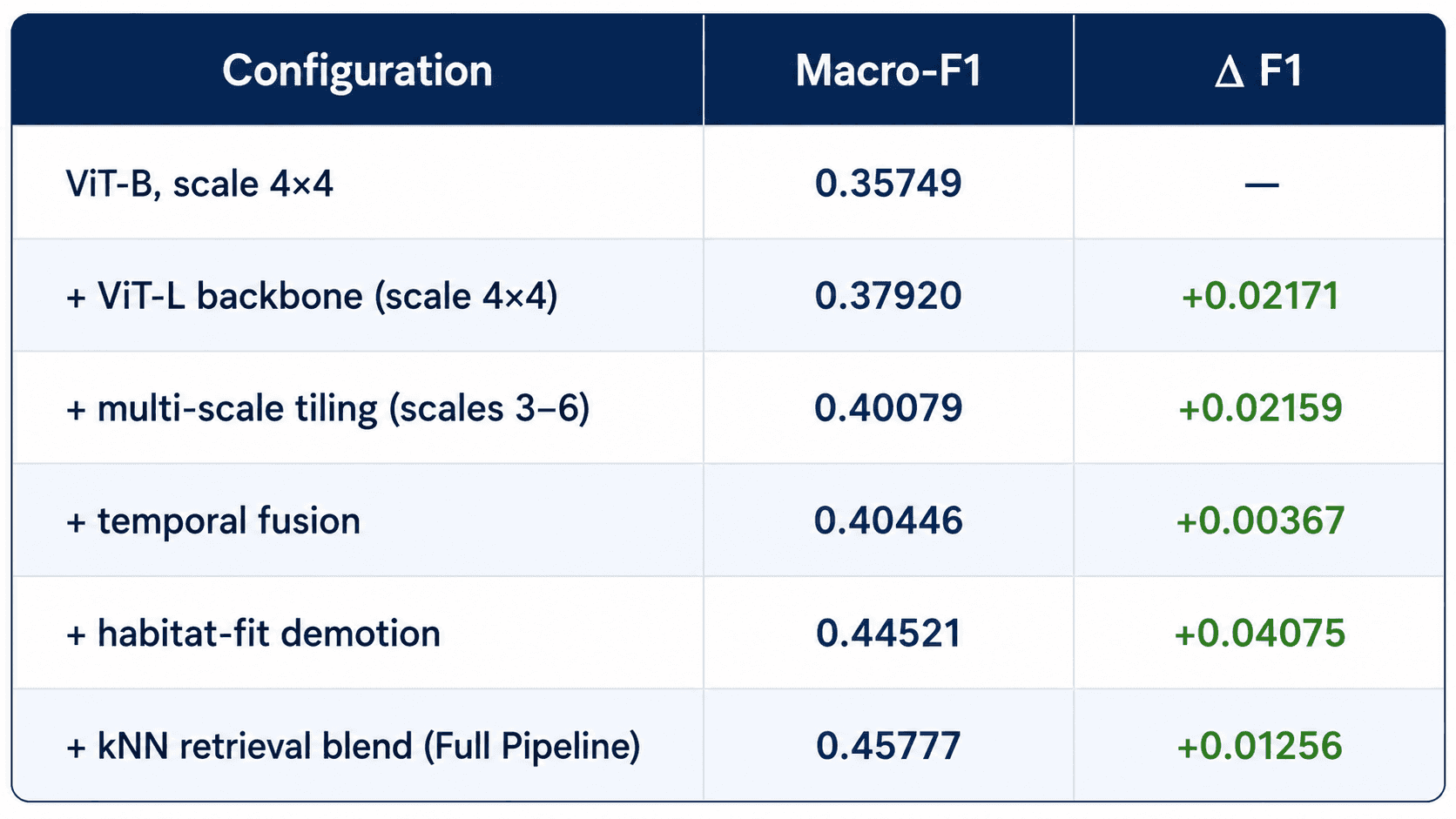
Several patterns emerge from these results. Habitat-aware post-processing produced the largest single improvement, contributing +0.04075 F1, nearly twice the gain of any other individual component. The ViT-L backbone and multi-scale inference each contributed approximately +0.022 F1, highlighting the importance of both model capacity and preserving fine-grained visual detail. The kNN retrieval blend provided an additional +0.013 F1, while temporal fusion delivered a smaller but consistent improvement.
Taken together, the results suggest that no single component was responsible for the final performance. Instead, the strongest gains came from combining multiple inference-time strategies designed to address different aspects of the train-test distribution gap.
Key Takeaways
1. Designing Around the Test Distribution: The largest improvements came from components specifically designed to bridge the gap between the training and evaluation distributions. Multi-scale inference, retrieval, temporal fusion, and habitat-aware post-processing collectively contributed more than any architectural modification explored during development.
2. Inference-Time Strategies Remain Underappreciated: PlantCLEF presents an extreme single-label to multi-label domain shift. In this setting, carefully designed aggregation and post-processing strategies consistently outperformed more complex training-centric extensions.
3. Context Matters: The highest-impact component in the final system was habitat-aware post-processing, which incorporated information unavailable to the image classifier itself. Geographic location, elevation, retrieval signals, and temporal consistency all provided useful context that could not be recovered from image pixels alone.
Code: github.com/dsgt-arc/plantclef-2026
Acknowledgements: This project was developed as a competitive submission for the DS@GT ARC research group alongside Murilo Gustineli and Adrian Cheung. The pipeline and experiments described in this article were independently designed and implemented by Alper Erten.
Compute resources were provided by the Partnership for an Advanced Computing Environment (PACE) at Georgia Tech.
Published June 2026
Feel free to connect via LinkedIn if you'd like to discuss computer vision, robotics, multimodal AI, or related opportunities.
Go back home