Coordinated Task Execution in Multi-Agent Reinforcement Learning: Overcooked-AI Study
PYTORCH
OPENAI GYM
PYGAME
This study evaluates multi-agent reinforcement learning (MARL) algorithms for cooperative planning in a discrete grid world using the Overcooked-AI environment. Three value-based deep reinforcement learning methods, Deep Q-Networks (DQN), Value Decomposition Networks (VDN), and QMIX, are benchmarked across two task layouts to examine the effects of coordination mechanisms, value factorization, and reward shaping under the centralized training and decentralized execution (CTDE) paradigm.
Environment and Problem Setup
Overcooked-AI is a two-agent simulator for cooperative cooking tasks involving discrete actions (move, stay, interact) and shared object interactions (onions, pots, dishes). Each 400-step episode rewards +20 for a completed soup, which requires placing three onions, cooking, and delivering.
State observations are 96-dimensional vectors encoding agent states, object positions, and environment structure. Although transitions are deterministic, tight coupling between agents creates a non-stationary learning problem. Sparse rewards and coordination demands make this a challenging MARL benchmark.
Algorithm Overview
Deep Q-Networks (DQN) is a single-agent off-policy RL algorithm extended here to two agents with independent learners. Each agent treats the other as part of the environment, resulting in unstable learning in highly coordinated tasks.
Value Decomposition Networks (VDN) learns individual Q-functions per agent and combines them via summation. This enforces decentralized execution while supporting shared training through centralized replay buffers. However, VDN assumes additive contributions, limiting expressiveness in environments requiring more complex cooperative credit assignment.
QMIX improves upon VDN by using a monotonic mixing network that conditions the value combination on the global state. A separate hypernetwork generates weights for the mixing function, enabling more complex interaction modeling while preserving CTDE compatibility.
All methods were implemented in PyTorch with shared network weights for symmetry. Q-networks (a.k.a. the agent networks) had a single hidden layer (64 units), layer normalization, and smooth L1 loss.
Training and Evaluation Setup
To address reward sparsity, additional shaped rewards were used during training, which included additional rewards for placing an ingredient in the pot (+2), picking up a dish (+1), or picking up a prepared soup (+2).
Agents were trained using an experience replay buffer, soft target network updates and a slow linear epsilon decay. An Adam optimizer with gradient clipping was used for all methods. Evaluations were conducted for 100 episode test rollouts without the exploration noise. Total number of soup deliveries were used as the primary performance metric during evaluation.
Summary of Findings
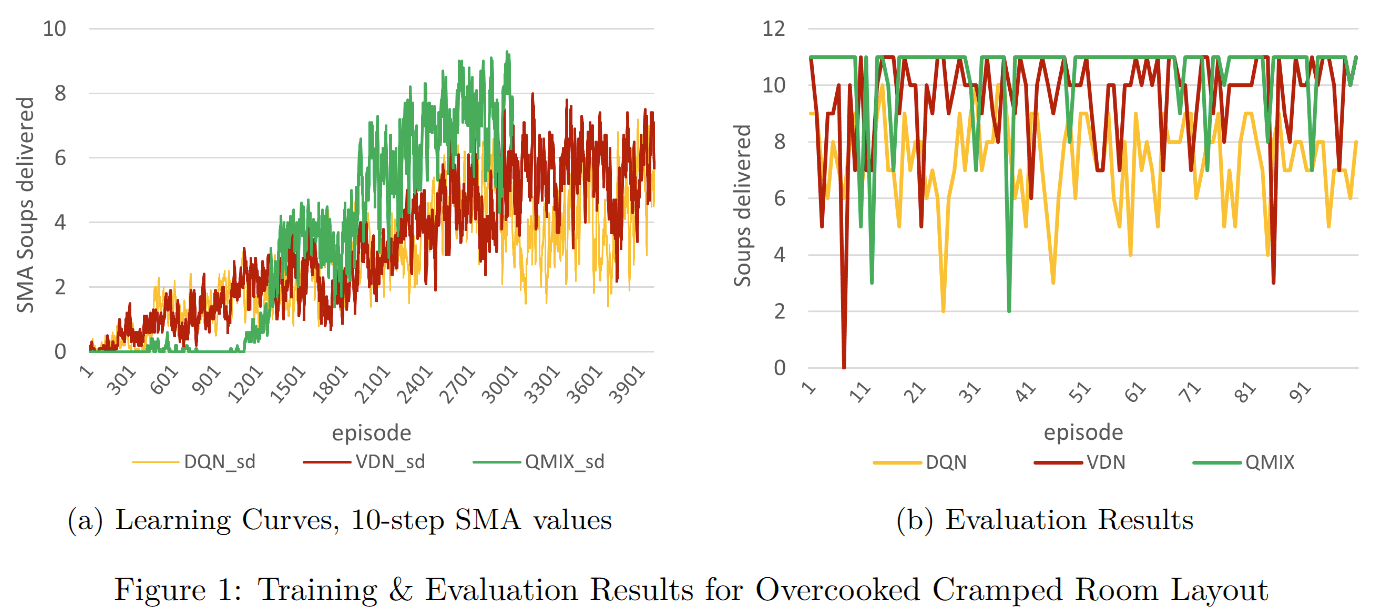
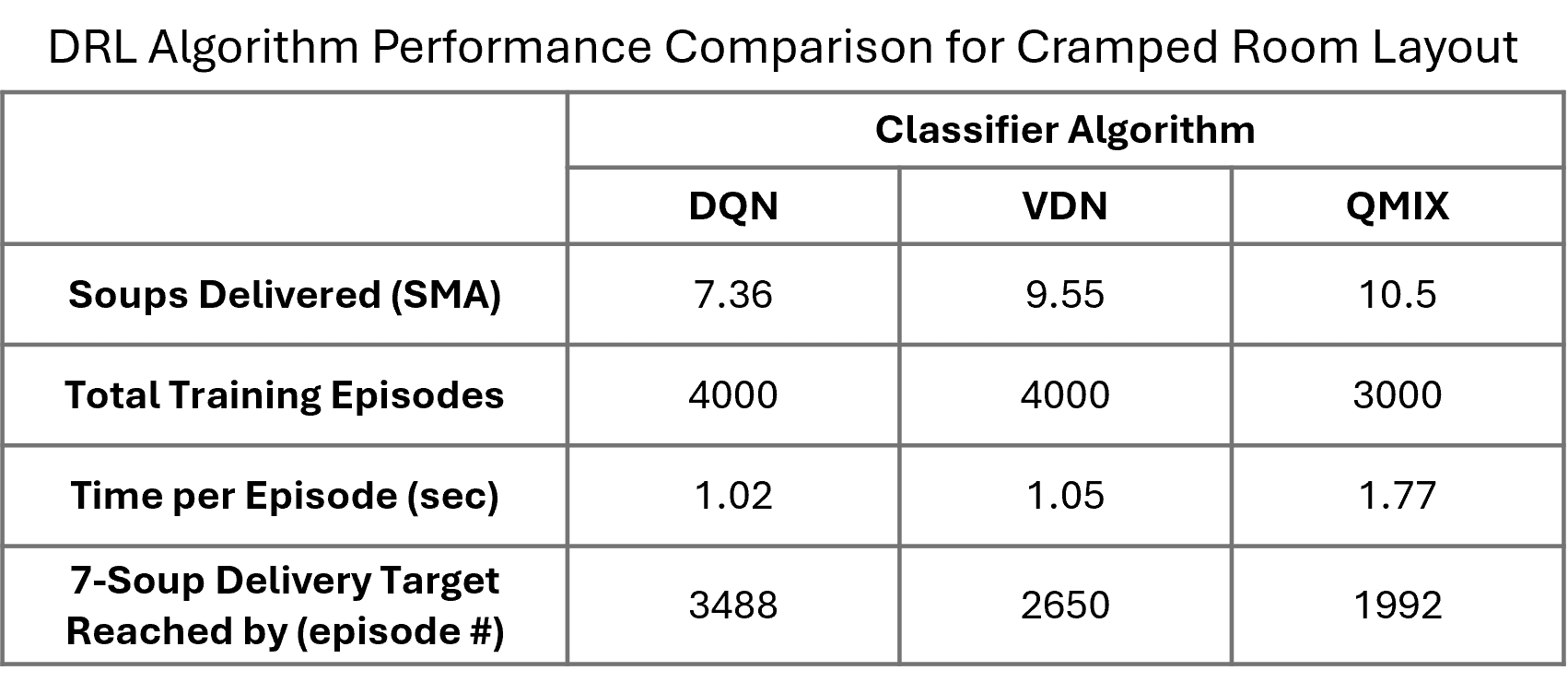
Cramped Room Layout
All algorithms converged within 4000 episodes. DQN plateaued early due to limited coordination capacity. VDN achieved strong results but flattened near 9 soups. QMIX required more computation per episode but reached higher peak performance with more stable Q-value estimates.

Key Takeaways
This benchmark study demonstrates the importance of value factorization in cooperative MARL. QMIX consistently outperformed DQN and VDN on tasks requiring coordination and credit assignment. Reward shaping and stable training schedules played a critical role in learning success, especially in constrained environments like Coordination Ring.
While DQN provided a fast baseline, its inability to model partner dynamics limited performance. VDN offered improvements but lacked sufficient expressiveness for high-coordination tasks. QMIX was the only algorithm to consistently reach optimal or near-optimal behavior.
These results emphasize the need for structured coordination modeling in MARL and position QMIX as a strong baseline for grid world-style cooperative tasks under CTDE training regimes.
Published August 2025
Go back home